Escardó’s Exhaustive Search: Part 1
Introduction
I’ve recently read this old blog post by Andrej Bauer about Martin Escardó’s Infinite sets that admit fast exhaustive search. At first, it seems pretty ridiculous! How is it possible to decide a problem that is embedded in an infinite topological space? However, using some nice tricks from functional programming and higher-level computability, we can achieve this and even explore some other unexpected consequences.
Any finite set is immediately exhaustible1, but the interesting thing is that certain infinite sequences with specific properties can also be exhaustible.
Notation
The simple types are . Let’s dig into this a bit more.
- the Booleans which in Haskell are
Bool = True | False - (natural numbers), written as
Int. - Product type is the Cartesian product, which is
IntMap a(Maybe a) - Function type
- = predicates on the naturals
- = boolean functions , etc.
Using these primitives, we can construct increasingly more complex types as:
Base case (level 0):
- = booleans
- = natural numbers
Level 1:
- = pair of booleans
(True, False) - = pair of naturals
(3, 7) - = boolean functions
{NOT, AND True, OR False, id, ...} - = predicates on naturals
{isEven, isPrime, λn.n>5} - = arithmetic functions,
{successor, λn.2*n, λn.n²}
type Oracle a = Int -> a -- ι → a (where a could be o, ι, etc.)
type Pred a = Oracle a -> Bool -- (ι → a) → o
type Prefix = IntMap Bool -- finite partial assignments - The domain is a Cantor space (all boolean streams)
- A predicate
pis a higher-type functional - a prefix
asgis a finite partial map which is used to define the cylinder sets used to define the product topology on the Cantor space.
Scott Domains
For each type , there is a Scott domain of partial functionals of the that same type defined by lifting the type to contain the undefined type with all of the properties you would expect (e.g. ordering, etc.). In Haskell, this looks like an Oracle a type with potential Need exceptions. This lets us capture the behavior of undefined/non-terminating computation, which we use to create partial oracles.
Total functionals
A functional is total if it maps total inputs to total outputs (so it never produces a Nothing type from non-Nothing)
evalP :: Pred a -> Prefix a -> Either Int Bool
evalP p asg = case unsafePerformIO (try (evaluate (p (oracle undefined asg)))) of
Left (Need i) -> Left i -- Partial: needs position i
Right b -> Right b -- Total on this prefixSo then we can evaluate where is a partial oracle depending on what the domain is.
Constructive Selection Functional for Cantor Space
Now consider the following code:
escardo :: Pred -> Maybe Oracle
escardo p = fmap extend (go IM.empty) where
extend asg i = IM.findWithDefault False i asg
go asg = case evalP p asg of
Right True -> Just asg
Right False -> Nothing
Left i -> case go (IM.insert i False asg) of
Just a -> Just a
Nothing -> go (IM.insert i True asg)We maintain a finite assignment asg that fixes the values of a few coordinates so far. evalP determines whether this cylinder already forces the truth value of p. If evalP p asg returns Right True, then is already true for every infinite bitstream extending asg. Then we can just stop and produce a total oracle by calling extend, which fills every unspecified bit (at this current point) with a default value (False).
But what does this mean? Think of the Cantor space as the set of all infinite binary sequences
From Wikipedia,
Given a collection of sets, consider the Cartesian product of all sets in the collection. The canonical projection corresponding to some is the function that maps every element of the product to its component. A cylinder set is a preimage of a canonical projection or finite intersection of such preimages. Explicitly, we can write it as:
So for the Cantor space, a cylinder consists of the set of all infinite strings that start with a finite prefix . For example,
[01]= all strings that start with “01”:
[101]= all strings starting with “101”:
We can illustrate this as a tree:
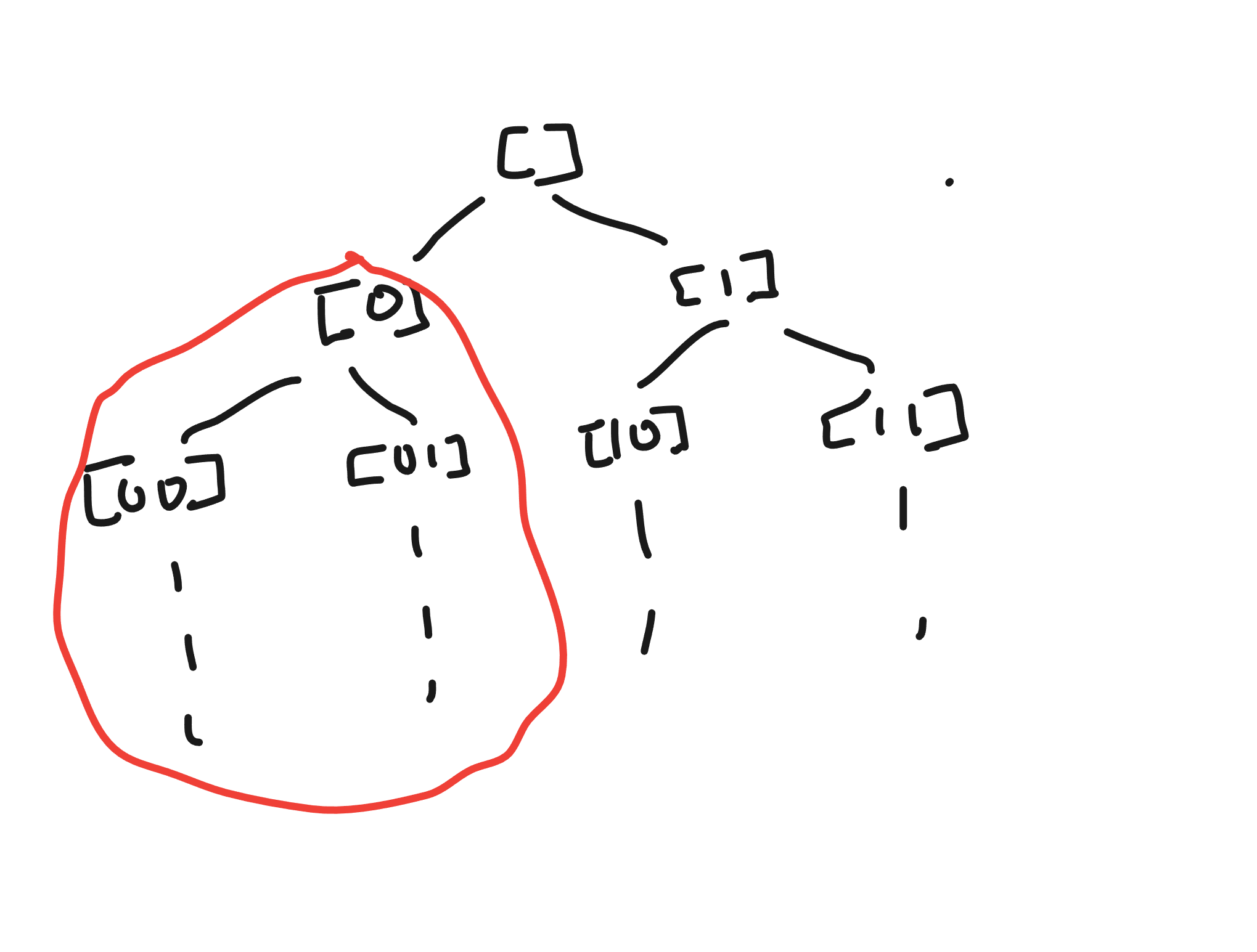
The cylinder set corresponds to the subtree circled in red in the case of the Cantor space.
So then, the search process starts at the root and recursively tries to decide on the current space (starting with the entire Cantor space). If we need bit , then split the current cylinder into two subcylinders. If a cylinder returns Right False, we abandon the subtree and if a cylinder returns Right True, we short-circuit and accept.
The incredible thing is that predicate in this case can be incredibly general. The simplest form to imagine are SAT-style boolean combinations, but they can be any continuous function decidable with finite information. For instance, all of the following are compatible with this framework and are decidable efficiently:
-- Arithmetic predicate
sumFirst10 :: Pred Int
sumFirst10 oracle = sum [oracle i | i <- [0..9]] > 50
-- Pattern matching
hasPattern :: Pred Bool
hasPattern oracle = any (\i -> oracle i && oracle (i+1) && not (oracle (i+2))) [0..97]
-- Convergence predicate
converges :: Pred Double
converges oracle = abs (oracle 100 - oracle 99) < 0.001and these aren’t easily expressible using an SAT-style alphabet. The key constraint is continuity, not logical structure.
for the sake of mathematical rigor
Recall that formally, the predicate is defined as a continuous map on the Cantor space, which itself is a countable product space. The basic open sets in this space are the aforementioned cylinders , which are infinite bitstreams that extend a finite assignment . By the (Kleene-Kreisel) continuity of , there exists some cylinder for each on which is already constant and hence a finite amount of information about the input fixes the output. Because the Cantor space is compact and totally disconnected, the preimages and are clopen, so each can be written as a finite union of cylinders (this is a pretty standard trick). Refining these finitely many cylinders to a common depth yields a uniform modulus2 (via Heine-Cantor) such that for each , is determined by some finite set of at most bits.
The evalP function implements this. Given a finite assignment (the IntMap), we run against the partial oracle that answers exactly the bits in and throws Need when an unassigned bit is requested. This is exactly the “dialogue” that Escardó describes in his paper: continuous higher-type functionals consuming only finite information..
So really, this is just an incredibly complex guided depth-first search over the binary decision tree of finite assignments that branches only when asks for a new bit with some short-circuiting logic. Termination relies on compactness via the uniform modulus . Left i can appear only when i is new (once a bit is assigned, accessing it later doesn’t throw a Need). Thus, no successful branch can be longer than , so after at most distinct queries continuity forces a Right answer. If p is everywhere false, the algorithm will explore all finitely many branches up to depth and fail and otherwise terminate early. Thus, we constructively determine that the Cantor space is searchable3. Another nice property of this is that the order that we sample branches doesn’t affect correctness, only runtime (so there are many engineering optimizations to be done…maybe Gray codes?).
The TL;DR is that:
- Continuity gives you cylinder-faithfulness
- Compactness gives you a uniform finite modulus
- Dialogue gives you an on-demand DFS that decides the predicate over finite information
why just the cantor space?
Good ol’ Wikipedia image. Unfortunately took me a few months to fully wrap my head around them.
The -adic integers4 can similarly be seen as an infinite stream of digits in the base much like the Cantor space (as shown above).
Really, the only difference is that now the alphabet size is now instead of restricted to . The Cantor space is kind of an artificial playground because conceptually it is pretty simple to understand. However, the -adics are widely applicable across number theory (Hensel’s lemma always surprises me) and more. We can easily compute the answer for the question “does there exist a -adic number that satisfies condition?” and construct a witness for it. At some point, i’ll implement a root finding constructive algorithm…maybe pure Haskell WolframAlpha??
There is also an extension of this that introduces Randomness and in turn has some interesting measure-theoretic and algorithmic properties..
Footnotes
-
A set is exhaustible if for any decidable predicate , there is a deterministic algorithm to determine whether all elements of satisfy . Formally, we can write that for a functional type with . The input is a predicate and the output is holds for all . ↩
-
From Wikipedia: a modulus of continuity is a function used to measure the uniform continuity of functions. So we can write ↩
-
A set is searchable if there is a computable functional such that for every defined on , and
Truefor some implies thatTrue. Thus, searchability exhaustibility ↩ -
Distance is measured as over the normal number line but in the -adic form, and . -adics also have cylinder sets (which are now residue classes ) and form the sasme tree-like structure where depth 1 represents mod 3 classes, depth 2 is mod 9 classes, etc. for . ↩